
「LLMには、どのようなセキュリティリスクが潜んでいるの?」
「LLMを安全に使うには、どんなセキュリティ対策が必要?」
ビジネスの現場で急速に活用が進むLLM(大規模言語モデル)。業務効率を飛躍的に向上させる一方で、その裏には特有のセキュリティリスクが潜んでいます。
LLMのセキュリティ対策を怠ると、機密情報の漏洩やシステムの乗っ取りといった重大なインシデントにつながり、企業の信頼を大きく損なうおそれがあります。LLMを活用するなら、具体的な脅威や対策方法を知っておきましょう。
本記事では、LLMのセキュリティについて以下の内容を解説します。
- LLMとは何か
- OWASPが発表した10のセキュリティリスク
- 効果的なセキュリティ対策の手法
本記事を読むことで、LLMを安全に活用するために必要なセキュリティ知識が身につくでしょう。LLMの導入を検討している方や、すでに活用している企業のセキュリティ担当者の方は、ぜひご一読ください。

LLMとは
LLMとは「Large Language Model(大規模言語モデル)」の略で、自然言語処理の分野で活用されるAI技術の一つです。大量のテキストデータを基盤にディープラーニングを用いて構築されており、人間が使う言葉を理解したり、新たに文章を生成したりできます。
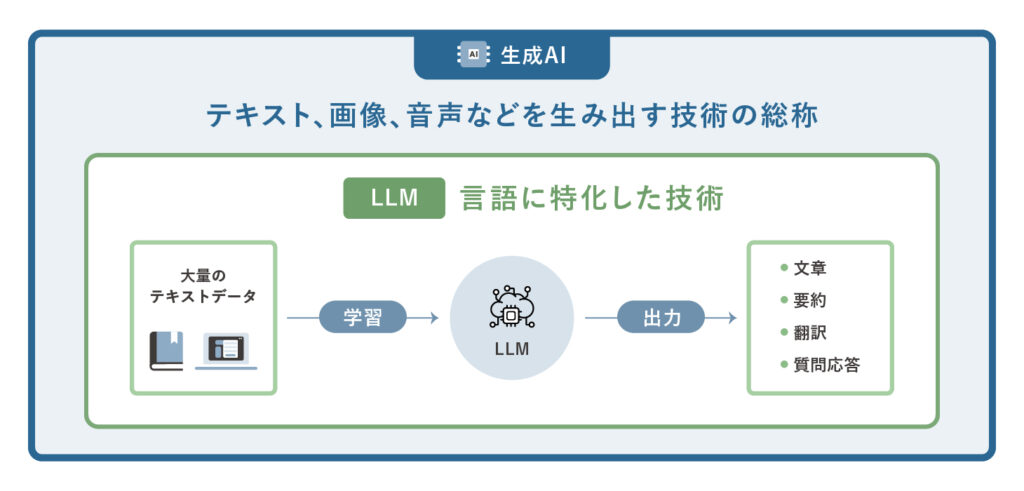
書籍や論文、Webページなど幅広い情報源から学習しているため、文章の生成や要約、翻訳、質問応答といった多様なタスクに対応できるのが特徴です。特に、従来の自然言語処理AIよりも文脈を捉えた自然な言語処理が可能であり、ビジネスや教育などさまざまな場面で活用が広がっています。
生成AIはテキストや画像、音声などを自律的に生み出す技術の総称ですが、LLMはその中でも「言語」に特化した技術です。生成AIの一種でありながら、膨大なテキスト学習を通じて高度な言語理解と表現を実現しています。
OWASPが発表したLLMのセキュリティリスク
LLMを活用するうえで避けて通れないのがセキュリティリスクです。国際的なセキュリティ標準を定める団体であるOWASPは、LLMを活用したアプリケーションに特有の脆弱性を「OWASP Top 10 for LLM Applications 2025」としてまとめ、特に注意すべき10項目のリスクを公開しています。
- プロンプトインジェクション
- 機密情報の開示
- サプライチェーン
- データとモデルの汚染
- 不適切な出力処理
- 過剰なエージェンシー
- システムプロンプトリーク
- ベクトルと埋め込みの弱点
- 誤情報
- 無制限の消費
1.プロンプトインジェクション
プロンプトインジェクションとは、ユーザーが入力する指示(プロンプト)を利用し、LLMに意図しない動作をさせる攻撃手法です。悪意のある第三者が特殊な命令をプロンプトに含めることで、開発者が設定した制約を回避させ、本来は許可されていない応答を引き出します。OWASPは、プロンプトインジェクションをLLMにおける最重要リスクの一つとして位置付けています。
プロンプトインジェクションによる被害は、単に不適切な応答が生成されるだけではありません。企業の機密情報が外部に漏洩したり、有害なコンテンツが作成されたりする危険性を伴います。さらに、不正な操作を誘発したり、組織の重要な意思決定に悪影響を及ぼしたりするなど、事業の根幹を揺るがしかねない事態に発展するおそれもあります。
プロンプトインジェクションの攻撃手口や対策などは以下の関連記事で解説しているので、併せてご覧ください。
▼関連記事

2.機密情報の開示
LLMや関連するアプリケーションが、意図せず機密情報を含んだ応答をしてしまうリスクも深刻な問題です。不正アクセスやプライバシー侵害、企業の知的財産が脅かされるといった、重大なインシデントに直結する可能性があります。
具体的には、個人を特定できる情報、医療記録、社外秘の業務データ、システムへのログイン情報などが、応答を通じて第三者の目に触れてしまう可能性があります。こうした情報漏洩は、個人のプライバシーを著しく侵害するだけでなく、企業の競争力を左右する重要な情報が流出する事態にも発展しかねません。結果として、企業の信頼を大きく損なう原因となり得ます。
3.サプライチェーン
LLMのサプライチェーンには、学習データや基盤となるモデル、利用するプラットフォームなど、多岐にわたる要素が含まれています。このサプライチェーンのいずれかで、意図的に汚染されたデータが混入したり、悪意のある改ざんが行われたりする危険性があるのです。
もし脆弱性が悪用されると、LLMの応答が偏ったものになったり、セキュリティ侵害を招いたりする可能性があります。最終的には、システム障害につながるおそれも。LLMは外部の学習データや公開モデルへの依存度が高いため、これらの外部要素の品質や安全性がシステム全体のセキュリティを左右することになります。
4.データとモデルの汚染
データとモデルの汚染とは、LLMの学習データやモデルそのものに、悪意のある操作が加えられるリスクを指します。攻撃者は、意図的に偏った情報や虚偽のニュースを学習データに混入させることで、LLMの知識基盤を歪めることが可能です。その結果、LLMは特定の思想に偏った回答を生成したり、誤った情報を事実であるかのように出力したりするようになります。
5.不適切な出力処理
不適切な出力処理とは、LLMからの応答を無条件に信頼してしまうことに起因するセキュリティリスクです。LLMが生成した出力を、十分な検証や無害化処理(サニタイズ)をせず後続のシステムに利用することで生じます。
具体的なリスクは、XSS(クロスサイトスクリプティング)やCSRF(クロスサイトリクエストフォージェリ)などです。ユーザーのセッション乗っ取りや不正なリクエスト送信を引き起こし、システムの安全性を大きく損ないます。
この問題は、LLMの出力がユーザーやシステムにどのような影響を及ぼすかを十分に検討しないと起こりやすくなります。開発者がLLMを過信し、出力内容の検証を怠ってしまうケースは少なくありません。安全性の高いシステム設計のためには、出力の検証と制御を必ず取り入れる必要があります。
なお、XSSやCSRFの脆弱性について詳しく知りたい方は、下記の関連記事をご覧ください。
▼関連記事


6.過剰なエージェンシー
過剰なエージェンシーとは、LLMに与えられた権限や機能が過剰であるために、意図しない破壊的なアクションを実行してしまう脆弱性です。エージェンシーとは「行動を起こす権限」を意味します。権限が適切に制限されていない場合、LLMが不要なデータにアクセスしたり、自己判断で予期せぬ動作を行うリスクが高まります。
7.システムプロンプトリーク
システムプロンプトリークとは、LLMの基本的な振る舞いを制御するために設定された指示(システムプロンプト)が、意図せず機密情報を含んでしまうリスクです。本来は外部に公開されるべきではない内部設定や命令が、出力や挙動を通じて漏洩してしまう可能性があります。
8.ベクトルと埋め込みの弱点
ベクトルおよび埋め込みの弱点とは、RAGを活用するLLMにおいて発生し得るセキュリティリスクを指します。RAGとは、外部データへの検索内容を組み合わせて回答精度を高める技術です。RAGが悪用されると、有害コンテンツの注入、モデル出力の操作、センシティブな情報へのアクセスといった攻撃が実行されるおそれがあります。
9.誤情報
LLMが事実とは異なる情報を、まるで真実であるかのように生成してしまう問題もあります。誤情報が発生する主な原因は「ハルシネーション」です。ハルシネーションとは、LLMが学習データに存在しない情報をあたかも事実であるかのように創作してしまう現象を指します。
利用者がLLMの生成したコンテンツを過信し、正確性を検証しないまま利用すると、誤情報による被害が広がってしまいます。最終的には、企業の評判低下や法的な責任問題にまで発展するおそれがあるでしょう。
ハルシネーションによる悪影響や対策方法は、以下の関連記事を参考にしてください。
▼関連記事

10.無制限の消費
LLMに対して過剰な処理要求が集中し、サーバーなどのリソースが際限なく消費されてしまう脆弱性も存在します。LLMは膨大な計算リソースを必要とするため、適切な制限なしに利用されると、システム全体のパフォーマンスや運用コストに深刻な影響を与える可能性があるのです。たとえば、負荷の高いリクエストが大量に送られると、サーバーが処理しきれずサービスが止まってしまうおそれがあります。
従業員の独断利用による「シャドーAI」のリスク
OWASP Top 10のようなシステム的な脆弱性対策も重要ですが、組織として見落としてはいけないのが、従業員の利用実態に起因するリスクです。
特に課題となりやすいのが「シャドーAI」です。これは、会社が許可していないAIツールやクラウドサービスを、従業員が独断で業務利用してしまう状態を指します。「業務を効率化したい」という善意であっても、無料のAIツールなどに機密情報を入力してしまえば、サービスの設定によってはデータが学習に再利用され、意図しない情報漏洩につながるおそれがあるのです。
システムへの攻撃を防ぐのと同時に、利用可能なツールを明確にするなど、運用ルールの整備も並行して進める必要があります。
▼関連記事

LLMの主なセキュリティ対策
LLMのセキュリティ対策では、先述したリスクを軽減するための実践的なアプローチが求められます。以下の3つのセキュリティ対策を実施することで、LLMの利便性を維持しながら、セキュリティリスクを最小限に抑えることが可能です。
- 入力データの検証と出力の監視
- アクセス制限
- 脆弱性診断
入力データの検証と出力の監視
LLMのセキュリティ対策において、基本となるのが入力と出力の両面における制御です。
入力時の対策では、入力データの検証・フィルタリングが有効です。ユーザーから与えられるプロンプトを厳格にチェックし、悪意のある指示や公開すべきでない機密情報がプロンプトに紛れ込んでいないか確認します。多層的なアプローチをすることで、プロンプトインジェクションやシステム悪用のリスクを大幅に低減できます。
さらに、LLMが生成した文章を監視・制御する取り組みも重要です。LLMが意図せず不適切な内容や内部情報を出力してしまうケースに備え、生成されたテキストをリアルタイムで監視する体制が求められます。
| 区分 | セキュリティ対策 | 内容 |
| 入力 | 禁止ワード・パターンのフィルタリング | 特定のNGワードや危険な命令パターンを検出し、入力を拒否・修正する |
| 意味論的フィルタ・コンテキストチェック | 言葉の意味や文脈を解釈し、単語レベルでは見抜けない不適切な入力を検出する | |
| 権限チェックとユーザー識別 | ユーザーに与えられた権限の範囲内でリクエストが実行されているかを確認する | |
| サイズやタイミングの検証 | 入力データのサイズやリクエストの頻度に制限を設け、異常なアクセスを遮断する | |
| 出力 | ログ監視 | 出力内容やアクセスを詳細に記録し、不正利用を検知・対応する |
| ポリシー違反の検出・対応 | 出力がポリシーや法規制に違反していないか確認し、違反時は修正・ブロックする | |
| 有害コンテンツのフィルタリングと無害化処理 | 出力に攻撃コードやスクリプトが含まれていないか検査し、必要に応じて無害化する | |
| 機密情報の検知とマスキング | 出力に個人情報や社内秘の情報が含まれていないかを監視し、自動でマスキングや削除を行う |
入口で不正な命令を遮断し、出口で問題のある出力を食い止めるという二段構えの対策によって、LLMを安全に運用するための基盤を構築できます。
アクセス制限
LLMシステムやWebアプリケーションに対して、アクセスできる機能やデータの範囲を厳密に制御することも、不正利用や情報漏洩を防ぐ上で重要です。もしLLMに必要以上の権限が与えられていると、攻撃者にその権限を悪用され、意図しない操作を実行される危険性が高まります。そのため、LLMがアクセスできる範囲を、その役割に応じて必要最小限に留める管理が求められます。
また、LLMの実行環境を「サンドボックス化」するのも有効です。サンドボックスとは、他のシステムから隔離された安全な仮想環境を指します。サンドボックスでファイルシステムや外部リソースとのやり取りを制限すれば、攻撃経路を最小限に抑えることが可能です。
脆弱性診断
LLM活用におけるセキュリティ対策では、LLMそのものに起因するリスクに注目が集まりがちです。しかし、LLMが出力したデータの利用先にも目を向ける必要があります。
たとえば、LLMをシステム開発のコード生成に利用する場合、LLMの出力に不適切なコード(XSS/CSRFなど)が含まれている可能性があります。それを無害化する処理が不十分であれば、システムが攻撃を受けるリスクにつながります。そのため、最終成果物自体への脆弱性対策も行い、多層的な対策を講じることで、サプライチェーン全体を守る姿勢が不可欠です。
また、LLMをWebアプリケーションに組み込む場合も、その土台となるアプリケーションに潜む脆弱性への対策は無視できません。
そこで有効なのが、定期的な「脆弱性診断」の実施です。診断を行うことで、Webアプリケーションに潜む脆弱性をいち早く検出し、被害が発生する前に対応できます。どれほど注意を払っていても脆弱性を完全にゼロにはできないため、継続的な検査と改善が重要です。
脆弱性診断の詳しい内容は、以下の関連記事をご覧ください。
▼関連記事

LLM活用を支える「AIセキュリティ」の包括的な視点
ここまでLLM特有のリスクと対策を解説してきましたが、LLMセキュリティを語る上では、AIシステム全体に共通する「AIセキュリティ」の観点も欠かせません。AIセキュリティとは、外部からの攻撃を防ぐだけでなく、データの信頼性確保やモデルの盗用防止、さらにはガバナンス(運用統制・リスク管理)までを含んだ包括的な概念です。
LLMをビジネスの中核に据えるのであれば、開発から運用までを含めたAIライフサイクル全体を見据えたガバナンス体制の構築が不可欠です。ガイドラインを策定してルールを明確に定め、従業員に周知しましょう。
組織全体でどのようにAIセキュリティを強化するかの視点を取り入れると、より運用の実効性が高まります。
▼関連記事

まとめ|LLM対策でセキュリティを強化しよう
LLMとは大規模言語モデルのことで、膨大なテキストデータから学習し、人間のような自然な文章を生成できるAI技術です。LLMの利便性は高い一方で、OWASPが発表した10のセキュリティリスクに適切に対処しなければ、情報漏洩などの被害を招く可能性があります。
LLMのセキュリティを確保するためには、本記事で解説した以下の対策が重要です。
- 入力データの検証と出力の監視
- アクセス制限
- 脆弱性診断
特に、AIを搭載したアプリケーションの複雑なセキュリティリスクにも対応したい場合は、高精度な診断機能を提供するAeyeScanの活用が有効です。AIに起因するものも含め、Webアプリケーションの脆弱性を幅広く検出できます。セキュリティレベルを向上させたい方は、まずAeyeScanの資料をダウンロードして詳細情報を確認してみてください。



